
 ENGELS
ENGELS DUITS
DUITS FRANS
FRANS SPAANS
SPAANS PORTUGEES
PORTUGEES ITALIAANS
ITALIAANS TSJECHISCH
TSJECHISCH POOLS
POOLS
Hoe een boek op de juiste manier scannen
Het is heel gemakkelijk om zelf een boek te scannen.
Om een boek op uw thuisscanner te scannen, hebt u ScanPapyrus-software nodig. ScanPapyrus helpt bij het converteren van een boek naar de digitale kopie.
ScanPapyrus helpt bij het omzetten van een papieren boek naar een digitaal exemplaar.
Zonder dit programma zal het scanproces ingewikkelder zijn. Stel je voor dat je Geen ScanPapyrus hebt en je wilt een boek scannen.
Laten we eerst eens tellen hoeveel pagina's er in je boek staan. 100? 200? Dat betekent dat je de scan 200 keer moet uitvoeren. 200 keer zal de scankop langs de glasplaat gaan. Je kan de pagina's toch ook in één keer scannen en dan handmatig de pagina's scheiden?
Ok, laten we zeggen dat we 100 pagina's hebben gescand met elk 2 pagina's, en ze dan hebben gescheiden naar 200 individuele pagina's. Dus, nu hebben we 200 bestanden met afbeeldingen, en we moeten ze comprimeren in een PDF bestand. Dus moeten we een programma vinden dat dit kan, kijken of het kan wat we willen, dan misschien een ander programma zoeken, enz.
Met ScanPapyrus is het proces veel eenvoudiger.
Ten eerste is ScanPapyrus een alles-in-één pakket. Het bevat tools voor het scannen en bewerken van afbeeldingen en voor het exporteren naar verschillende formaten (PDF, DjVu).
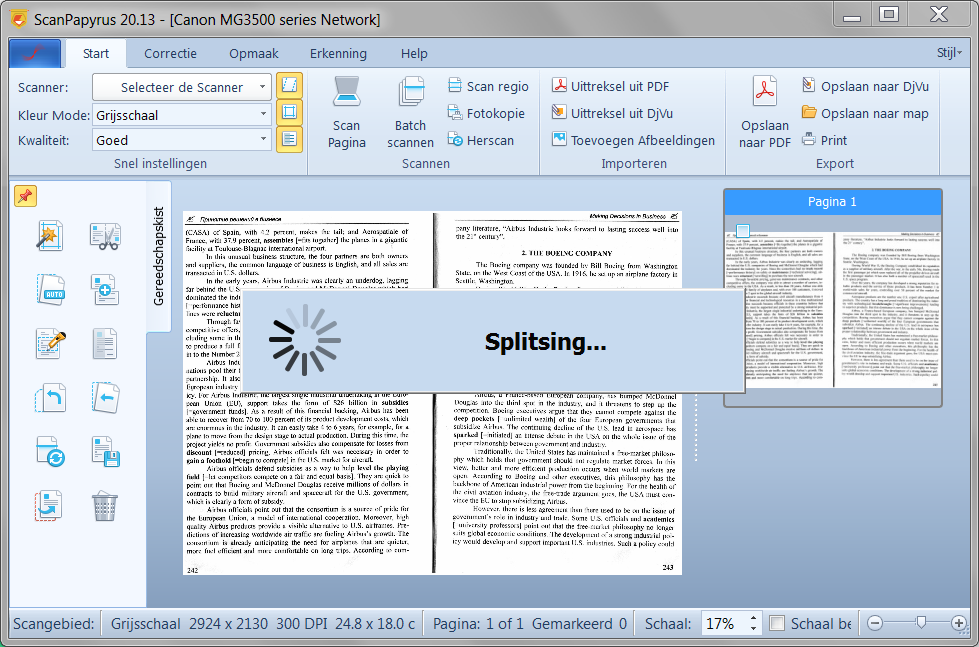
Ten tweede, met ScanPapyrus hoef je niet elke pagina afzonderlijk te scannen of tijd te verspillen aan het scheiden van pagina's op twee pagina's. Je scant gewoon de hele spread en ScanPapyrus maakt er automatisch twee afzonderlijke pagina's van! En dat is het! Je hoeft niets te doen, behalve dit. De rest wordt gedaan door ScanPapyrus.
In combinatie met de automatiseringsmogelijkheden wordt het scannen van een boek uiterst eenvoudig. Start het scannen in de automatische modus, en voer de scanner één voor één met pagina's. Het programma ontvangt de beelden van de scanner en splitst ze op in pagina's. Bovendien worden pagina's automatisch verwerkt - het programma verwijdert onnodige marges, herstelt schuine pagina's en maakt de achtergrond lichter. Als het scannen klaar is, selecteer je gewoon het uitvoerformaat: DjVu, PDF, of een reeks afbeeldingen voor verdere OCR.
Laten we het scannen van boeken eens in detail bekijken.

Het scannen van de boeken
Om het automatisch scannen van een boek te starten, klik je op de knop Batch scannen op de werkbalk. De wizard Scannen wordt geopend. Geef de scaninterval op in de wizard. Aangezien het verwerken van afbeeldingen en het splitsen in pagina's enige tijd in beslag neemt, zijn 3-5 seconden voldoende om de pagina van het boek om te slaan en de volgende paginaspread op de scanner te leggen. Je kan het deksel omhoog laten als je dat wil: ScanPapyrus zal automatisch onnodige marges afsnijden.
De Scan de eerste pagina meteen optie betekent dat het scanproces onmiddellijk start nadat je op de "Volgende" knop klikt. Als de optie uit staat, wordt de scan uitgevoerd nadat de opgegeven scaninterval is verstreken.
De optie Splits het boek verspreid in twee pagina's is de belangrijkste optie bij het scannen van boeken. Het is deze optie die de gescande afbeeldingen in twee afzonderlijke pagina's scheidt. Als de optie niet is ingesteld, behandelt ScanPapyrus de gescande afbeelding als een enkel A4-vel.
Dus, zet de Splits het boek verspreid in twee pagina's optie aan, plaats de paginaspread op de glasplaat van de scanner, en klik op de Start knop. Het scannen begint, en de paginaspread wordt gescand.
Verwerking van het verkregen beeld
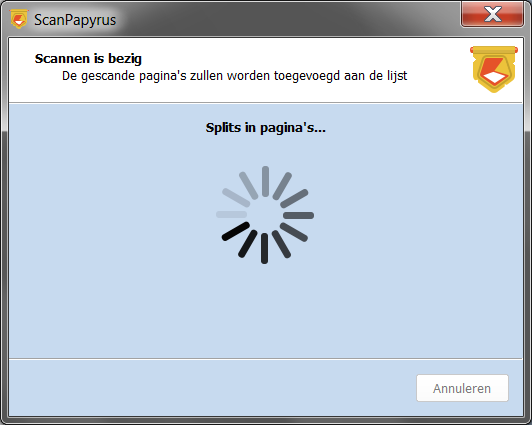
Zodra de scanner klaar is met scannen, begint de beeldverwerking. Afhankelijk van de opgegeven instellingen worden de volgende acties ondernomen:
1. Beeldbewerking: d.w.z. zwarte stroken en overmatige marges worden verwijderd, de achtergrond wordt aangepast zodat deze meer wit is, en schuine en gebogen afbeeldingen worden gefixeerd, wat betekent dat als het boek onder een bepaalde hoek op de scanner wordt gelegd, deze hoek wordt gecompenseerd.
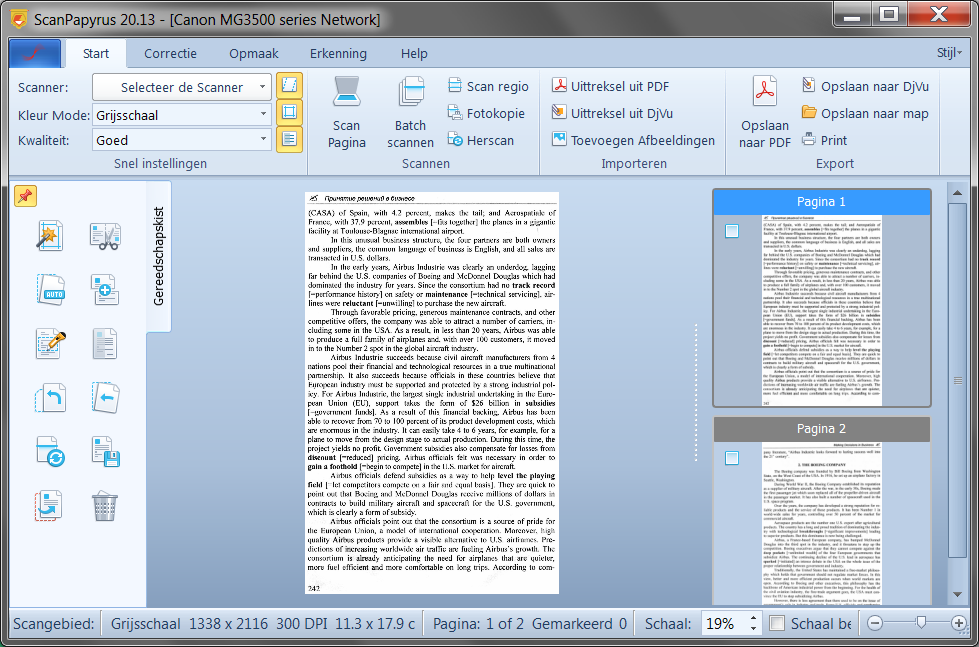
2. Afbeeldingen scheiden naar twee afzonderlijke pagina's.
Laten we de laatste optie eens in meer detail bekijken. Het programma gebruikt de vouwlijn als een indicator voor de paginascheiding. Als die er niet is, kan het resultaat onvoorspelbaar zijn. Wanneer je echter een paginaspread van het boek scant, is de vouwlijn er altijd.
Scannen van het volgende boek
Als resultaat van de vorige stap krijg je twee pagina's, en die zijn al toegevoegd aan het project. Je kan ze zien in de lijst met pagina's. Het is belangrijk om het boek in de juiste richting te plaatsen, maar zelfs als je het ondersteboven legt, kun je gewoon de Rotate functie van het programma gebruiken om dergelijke afbeeldingen snel de juiste kant op te draaien.
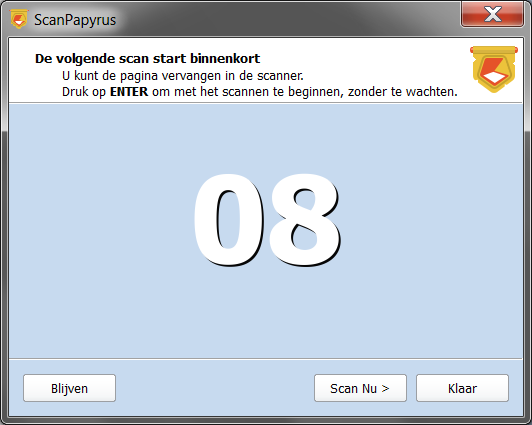
Bij de derde stap wacht het programma een bepaalde tijd, zodat je de pagina kunt omslaan en de volgende boekspread op de scanner kunt leggen. Je kan de timer stoppen met de knop Pauze of door gewoon op de spatiebalk van het toetsenbord te drukken. Als je klaar bent met het scannen van het boek, klik je op de knop Klaar. Om het gepauzeerde scannen te hervatten, klik je op de knop Scan Nu > of druk je op Enter.
Het resultaat is een gescand boek dat je kan opslaan als PDF of DjVu.
NAVIGEREN
OVER ONS
ScanPapyrus Team ontwikkelt thuis- en kantoorapplicaties voor Windows. Onze programma's staan bekend om hun hoge kwaliteit, gebruiksvriendelijkheid en uitgebreid ontwerp.
PARTNERS
![]()